How useful is GPU manufacturer TDP for estimating AI workload energy?
Manufacturer provided Thermal Design Power (TDP) figures are often used to estimate energy consumption of GPU AI workloads, but how useful are they?


The biggest challenge with assessing the energy impact of AI workloads is the lack of data. Model developers rarely publish useful data about the machines, configuration, training time, or any other figures that could be used to calculate how much energy was involved.
Despite this, we still get weird and wonderful estimates such as “A single ChatGPT conversation uses about fifty centilitres of water, equivalent to one plastic bottle.” (Forbes) and total ChatGPT energy consumption being enough to charge every EV in the United States four times (BestBrokers).
Without commenting specifically on these particular estimates, the first question to ask whenever you see any of these claims is: what is the methodology behind the calculation?
As we found in the data center energy review I co-authored, most of the ridiculous estimates are a result of extrapolation. If power consumption was x for y users in the past, let’s just figure out how many more users there will be and assume the energy consumption is the same for each user1.
Estimating power consumption (x) is where you should pay attention.
Thermal Design Power (TDP): Keyword “maximum”
In the absence of actual energy measurements, estimations often look to the manufacturer specifications. These are useful to understand the maximum power draw of a particular component or system.
The key word there is maximum.
For example, an Nvidia H100 SXM GPU TDP is (up to) 700W. The H100 DGX node is 10,200 W. These can be seen from the datasheet:

A common error is to take TDP as the actual power draw, but that is rarely achieved. To produce accurate estimates for real workloads, you have to measure the actual power draw of the system under realistic conditions. This is time consuming and expensive, so most people don’t bother.
For servers, the SPECpower database is often used because of the test runs, but the same type of data isn’t available for GPUs.
Evaluating the Node Level Power Draw
At the Open Compute Global Summit in October 2024, Alex Newkirk gave a great presentation of real world measurements he and his team conducted for real AI workload power draw. This used a DGX H100 node to run training for Resnet 2, LLAMA-13b, and several other open source training sets from the MLPerf™ Training v4.0 benchmark.
It’s worth watching the short presentation, but the highlights are:
Workload configuration had a significant impact on energy usage. Using higher batch sizes caused higher instantaneous power demand, but used less energy overall.
The number of nodes had an opposite effect - more nodes resulted in shorter training time, but more energy use.
The manufacturer TDP was never reached, even with more model parameters. A good rule of thumb is 75% of TDP, but even that shows a wide range.


So many parameters
The talk also mentioned a 2023 preprint from Wang et al. which highlighted the difference between node generations: Nvidia RTX 8000 vs A-100.
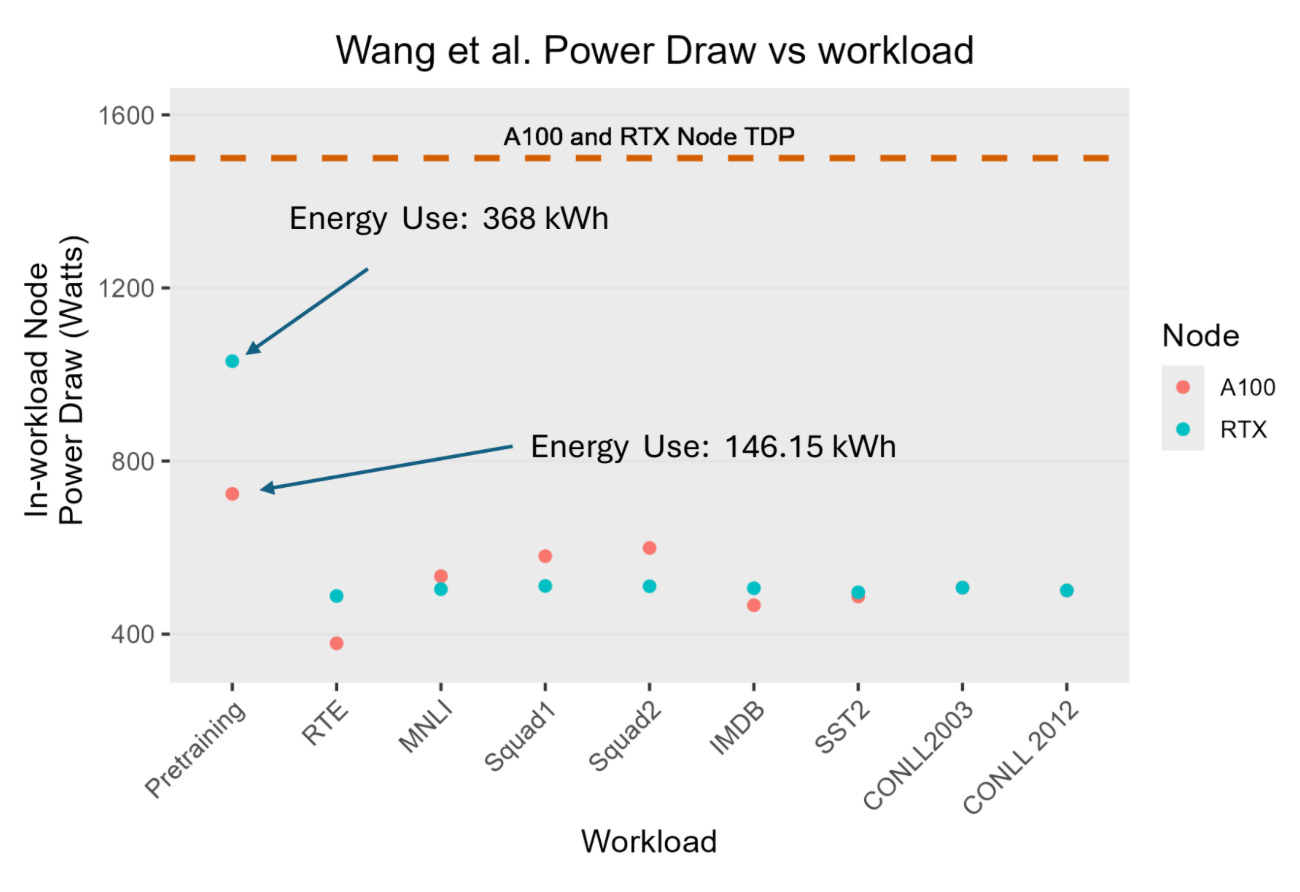
This backs up a 2022 Google paper which showed how model choice and hardware generation make a major difference in energy consumption (see my post about it).
Timestamp estimates
Any estimate must include a timestamp because training costs are falling rapidly. From Sam Altman:
The cost to use a given level of AI falls about 10x every 12 months, and lower prices lead to much more use. You can see this in the token cost from GPT-4 in early 2023 to GPT-4o in mid-2024, where the price per token dropped about 150x in that time period. Moore’s law changed the world at 2x every 18 months; this is unbelievably stronger.
This is especially a problem for academic research because of the incredibly slow pace. It’s common for papers to take 1-2 years to be published, by which time they are entirely out of date. The only way to assess them is precise dates are provided.
If model developers released more data about the energy profile of their training runs then we’d have a clearer picture. In the absence of this, be careful when you come across AI energy estimates - understanding data center energy is difficult enough. AI energy consumption is even more challenging.
It may be a bit more sophisticated than that, but not much.
@davidmytton David, thank you for your kind words about my talk! If anyone is interested, we turned that talk into a paper, and the preprint is live (https://arxiv.org/abs/2506.14551) with prettier plots.